 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfoQuant: Shaping Activation Distributions for Low-Bit LLM Quantization
May 25, 2026Low-bit activation quantization remains a major bottleneck in efficient large language model (LLM) deployment. The difficulty is not only that activations contain outliers, but that their distributions are often poorly matched to a low-bit uniform quantizer. Existing post-training quantization (PTQ) methods suppress peaks, balance channels, or minimize reconstruction error, yet they rarely specify what activation distribution is actually easy to discretize. As a result, activations may appear numerically smoother while still incurring large quantization error because the quantization range remains wide or most values collapse into a few levels near the mean. We recast activation transformation as quantizer-facing distribution design and analyze quantization error from an information-theoretic perspective. Our analysis shows that quantization-friendly activations should jointly have a smaller numerical range and sufficient dispersion within that range. Guided by this analysis, we propose InfoQuant, a train-free method that employs Peak Suppression Orthogonal Transformation (PSOT) to shape activations into more quantization-friendly distributions. We further introduce adaptive outlier-token selection to improve the robustness of PSOT during optimization. Across multiple LLM families, InfoQuant consistently outperforms prior PTQ and end-to-end training baselines. Under W4A4KV4, it preserves 97% of floating-point accuracy on average and reduces the LLaMA-2 13B performance gap by 42% over the previous state of the art. Code is available at [https://github.com/LLIKKE/InfoQuant](https://github.com/LLIKKE/InfoQuant)
HybridGNN: Learning Hybrid Representation in Multiplex Heterogeneous Networks
Aug 03, 2022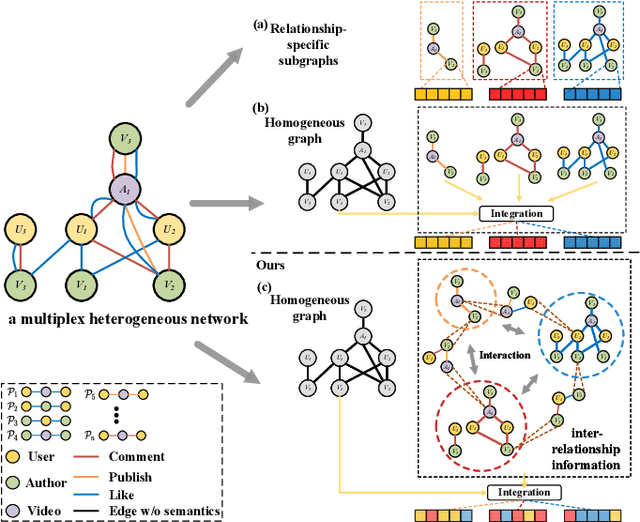
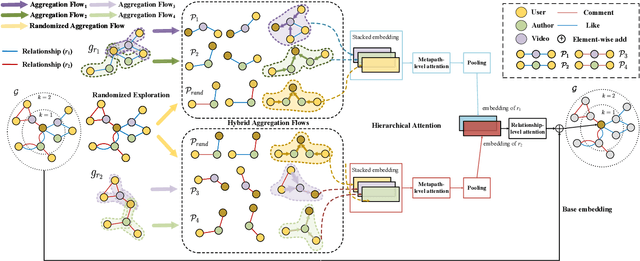
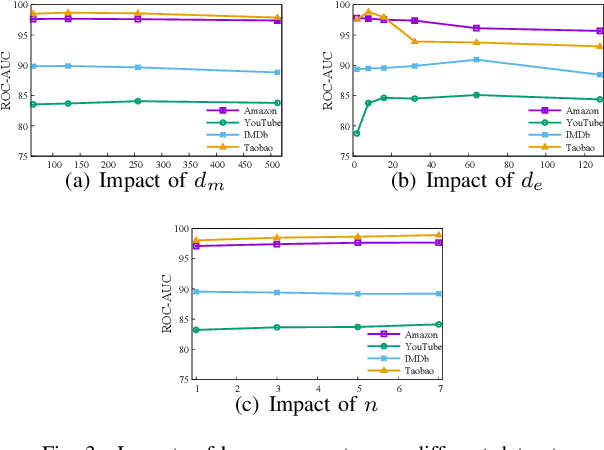
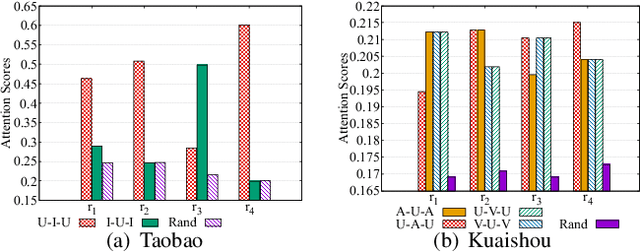
Recently, graph neural networks have shown the superiority of modeling the complex topological structures in heterogeneous network-based recommender systems. Due to the diverse interactions among nodes and abundant semantics emerging from diverse types of nodes and edges, there is a bursting research interest in learning expressive node representations in multiplex heterogeneous networks. One of the most important tasks in recommender systems is to predict the potential connection between two nodes under a specific edge type (i.e., relationship). Although existing studies utilize explicit metapaths to aggregate neighbors, practically they only consider intra-relationship metapaths and thus fail to leverage the potential uplift by inter-relationship information. Moreover, it is not always straightforward to exploit inter-relationship metapaths comprehensively under diverse relationships, especially with the increasing number of node and edge types. In addition, contributions of different relationships between two nodes are difficult to measure. To address the challenges, we propose HybridGNN, an end-to-end GNN model with hybrid aggregation flows and hierarchical attentions to fully utilize the heterogeneity in the multiplex scenarios. Specifically, HybridGNN applies a randomized inter-relationship exploration module to exploit the multiplexity property among different relationships. Then, our model leverages hybrid aggregation flows under intra-relationship metapaths and randomized exploration to learn the rich semantics. To explore the importance of different aggregation flow and take advantage of the multiplexity property, we bring forward a novel hierarchical attention module which leverages both metapath-level attention and relationship-level attention. Extensive experimental results suggest that HybridGNN achieves the best performance compared to several state-of-the-art baselines.